Datenschatz im Bundestag
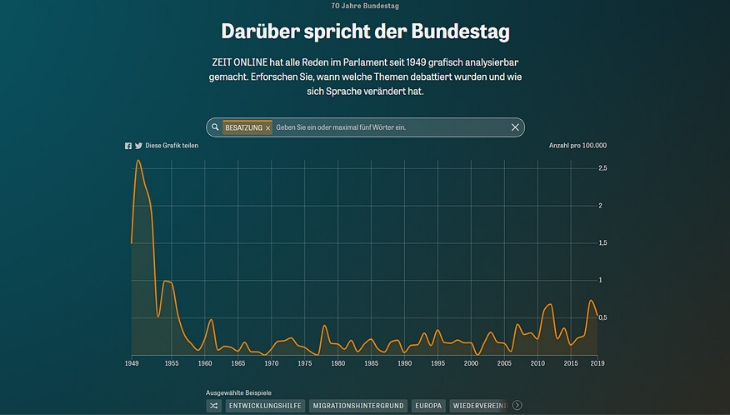

70 Jahre Reden im Bundestag, über 4.000 Sitzungen, mehr als 200 Millionen transkribierte Wörter. „ZEIT ONLINE“ hat diesen Datenschatz gehoben und aus den Textdateien der Aufzeichnungen eine interaktive Datenbank erstellt, die systematisch durchsuchbar ist. In „Darüber spricht der Bundestag“ lässt sich herausfinden, über welche Themen im Lauf der Jahrzehnte besonders viel gesprochen oder wann ein Wort das erste Mal erwähnt wurde.
„Darüber spricht der Bundestag“ ist für den Grimme Online Award in der Kategorie „Information“ nominiert. Im Interview erzählt Sascha Venohr, Mitglied der Redaktion, über die Schatzsuche und -bergung.
Wie kam es zu der Idee, sich in dieser Art mit dem Bundestag auseinanderzusetzen?
Das ist ein Projekt, das wir schon länger auf der Liste hatten, weil wir immer diese Protokolle auf der Bundestagsseite gesehen haben. Und wir haben gedacht, dass das ein Projekt wäre, wo wir sehr viel Spaß dran haben würden, diesen Schatz zu heben. Das Problem bei diesen zeitlosen Projekten ist, dass man sie immer wieder schiebt. Aber dann haben wir uns gesagt, das machen wir jetzt. Da springen wir jetzt rein. Es fing dann spielerisch an. Wir haben uns die ersten Kurven angeschaut und gemerkt, da steckt Potenzial drin und das wollen wir jetzt auch unseren Leser*innen zeigen.
Wie sind Sie dabei vorgegangen?
Wir nennen das immer ‚Daten putzen‘. Zunächst mussten wir diese Files, die auf der Bundestagsseite waren, für Maschinen lesbar machen, sodass wir auch tatsächlich diese Muster sehen können. Der größte Teil dieser Jahrzehnte liegt als reine Textdatei vor, ohne irgendeine Struktur. Wir mussten also erst mal an bestimmten Markern im Text feststellen, wann hat die Sitzung begonnen, wann war sie beendet. Man muss wissen, dass auch Dokumente oder Reden zu Protokoll gegeben werden können, die aber gar nicht im Plenum besprochen wurden. Diese Passagen mussten wir in den Dokumenten identifizieren, um somit wirklich das, was als Debattenbeitrag im Plenum formuliert wurde, durchsuchbar zu machen. Dann musste man natürlich auch noch die Namen herausfiltern, weil es keinen Sinn macht, dass der Name des Sprechenden durchsuchbar gemacht wird. Wir mussten versuchen, diese Struktur, die wir uns vorstellten, auf diese Datenbank zu übertragen. Dann fängt man an, sich mit einem einfachen Tool diese Muster anzuschauen. In der Redaktion gibt es immer eine Wand, die volltapeziert ist mit Ausdrucken. Immer, wenn jemand etwas Spannendes gefunden hat, ist er aufgesprungen und hat es an die Wand gehängt. Und so ist dann auch die Geschichte entstanden. Dann war aber auch klar, der Suchdrang ist so groß, es macht so Spaß mit diesem Tool zu spielen, dass wir das den Lesern auch geben müssen. Das Eine wäre ja nun, einfach Fundstellen zu identifizieren und zu zeigen. Wir wollten dann aber auch ein Tool anbieten, mit dem man selbst arbeiten kann.
Wie lange haben Sie für das Ergebnis recherchiert?
Das lässt sich immer schwer beziffern, weil das natürlich ein Projekt ist, was im Tagesbetrieb parallel läuft. Ich würde sagen, dass wir wirklich fokussiert drei Wochen am Stück gearbeitet haben, wenn man es zusammenrechnet.
Gab es ein Ergebnis, das Sie selbst überrascht hat?
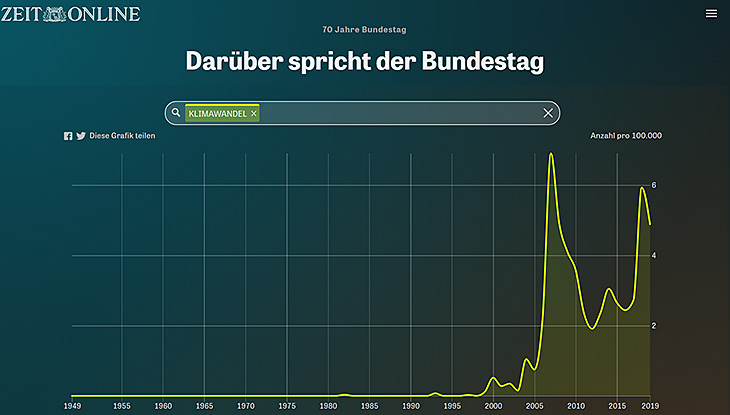
Es waren viele spannende Sachen. Wir haben ja auch den Nutzern selbst ermöglicht ihre Suchergebnisse auf Twitter zu teilen. Da wurde auch direkt ein Hashtag etabliert. #bundeswoerter haben wir das genannt. Und es war einfach sehr spannend zu sehen, wie die Leute mit diesem Tool gearbeitet haben. Am meisten hat mich persönlich überrascht, und ich glaube, das ist immer noch aktuell, wenn man im Homeoffice sitzt und über langsames Internet klagt, dass 1983 schon über Glasfaserkabel debattiert, aber nichts unternommen wurde. Das tut heute noch weh, das zu sehen.
Hatten Sie einen bestimmten Effekt im Kopf bei Ihrem Projekt?
Man muss sagen, es gibt wahrscheinlich nichts Trockeneres als das Thema ‚70 Jahre Bundestagsreden‘. Das ist wirklich nicht einfach zu verkaufen. Wir haben aber genau das Ziel gehabt. Wir wollten genau das geben und wollten es so aufbereiten, dass die Leute es auch wirklich nutzen. Wir hätten jetzt auch ein langweiliges Stück schreiben können über die spannendsten Debatten in den letzten 70 Jahren. Das hat man bestimmt auch gemacht. Aber hier ist ja die Chance, dass Daten einen ganz neuen Zugang bieten und deswegen war uns ganz wichtig, dass wir es auch so schlank wie möglich machen. Natürlich kann man mit semantischen Analysen und künstlicher Intelligenz noch viel tiefer einsteigen. Uns war es aber wichtig, dass alle verstehen, was dieses Tool macht und was es nicht macht. Nämlich einfach wirklich die Frequenz der Wörter zeigen. Natürlich kann man sagen, es gibt noch mal artverwandte Wörter und so weiter, aber es war uns wichtig, die Beispiele, die wir genannt haben, so zu Ende recherchiert zu haben, dass sie auch wirklich für etwas stehen. Natürlich kann man nicht ausschließen, dass es einzelne Fundstellen gibt, die auch in die Irre führen. Ein Beispiel: Wenn man das Wort ‚Liebe‘ eingibt, dann könnte man der Meinung sein, dass man den Anstieg und Abstieg von dem Begriff ‚Liebe‘ im Sinne von Zuneigung in den Parlamentsreden sieht. Das ist aber nicht der Fall, denn der Begriff ‚Liebe‘ wird einfach sehr häufig zu Beginn einer Rede genutzt. ‚Liebe Kolleginnen und Kollegen‘, ‚Meine lieben Damen und Herren‘. Das muss man einkreisen, aber das war für uns okay, weil wir eine schlanke und einfache Methodik anwenden wollten. Das hat unserer Meinung nach auch funktioniert, weil es eine sehr hohe Reichweite erzielt hat und gleichzeitig konnten wir sehen, dass die Menschen einfach auch sehr gerne ihre Fundstücke geteilt haben. Das ist das Wichtigste für uns: Ein Thema so aufzubereiten, dass wir mehr Leute erreichen, als das Thema von seiner mangelnden Attraktivität her verspricht.
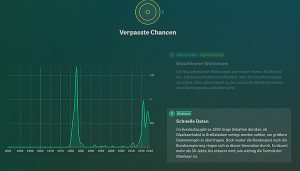
Sie stellen sich innerhalb des Projekts beispielsweise die Frage, warum sich in der Sprache der Redner das ‚Ich‘ zum ‚Wir‘ gewandelt hat und sagen, dass Ihre bisherige Analyse das nicht beantworten kann. Sind anschließende, tiefer gehende Projekte geplant? In den Kommentaren findet sich mehrfach der Wunsch danach.
Wir haben es zum jetzigen Stand nicht direkt geplant, aber es ist ganz klar, dass man da auch weitergehen muss bei diesem Datenschatz. Was wir bis jetzt gar nicht berücksichtigt haben, ist, wer etwas gesagt hat, also welche Partei welche Begrifflichkeiten verwendet. Das ist sicherlich die nächste Stufe, aber der nächste Schritt wird sein, die Daten zu aktualisieren. Wir sind ja jetzt beim Datenstand der Sommerpause. Das heißt, der letzte Stand der Datenbank ist die Vereidigung von Kramp-Karrenbauer zur Verteidigungsministerin. Da geht es auf jeden Fall noch weiter. Wir werden noch das Ende dieser Legislaturperiode abwarten und dann schauen, wie wir dort wieder einsteigen.

Dieses Interview führten Marie Jakob und Helen Dreyhaupt.








Hinterlasse einen Kommentar
An der Diskussion beteiligen?Hinterlasse uns deinen Kommentar!